在这个大模型(LLM)横行的时代,我们对AI的需求不仅仅是文本生成文本,很多平台都提供了文本生成图像(Text-to-Image) 的功能,比如GPT-4o两个月前推出的融合自回归模型(可见上一篇文章)和扩散模型等算法进行图像生成的新功能,在互联网上引发了一阵热潮……
我们对于这种多种模态信息(文本、图像、音频、视频)的融合学习就是**多模态学习综述(MultiModal Learning)**,实现跨模态的信息交互显然可以拓宽人工智能算法模型的工作范围。
一个学视觉算法的朋友在闲聊中提到CLIP模型是他们学习多模态几乎没法绕过的代表性模型,所以我去了解了一下,并尝试简单使用。
CLIP(Contrastive Language–Image Pre-training)
CLIP 是由 OpenAI 在2021年提出的模型,旨在将 图像和文本嵌入到同一个语义空间中,从而实现跨模态理解。它的基本机制是通过 对比学习(contrastive learning) 联合训练图像编码器和文本编码器。简单来说,我们以前单独将文本编码进行处理或者将图像编码进行处理,通过CLIP模型的思想,我们可以联合图像和文本的编码来一起处理两者。
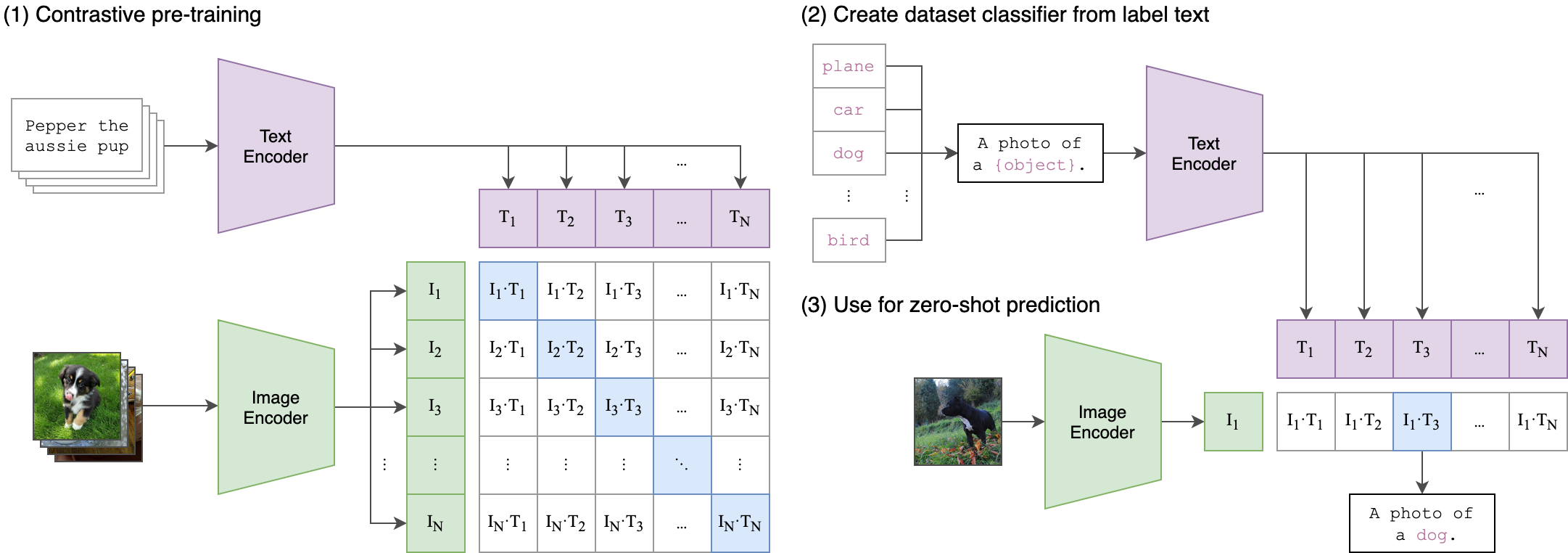
其实在文生图这样的任务中,我们已经不会只讨论CLIP,它更作为整个架构中的一个基础模型,就像CNN之于神经网络,不过是几层基础的网络层,并不太会单独拎出来讲。但是作为学习,我个人认为还是必要的。
因为CLIP 能“理解”文本和图像的语义对应关系,所以在文生图中可以用于指导图像生成的方向,比如在我们熟知的 Stable Diffusion 中(我大一还玩过秋葉大佬的整合包),CLIP 不参与图像生成本身,但在早期版本中常用于 图像质量评价或优化(如 CLIP-guided Diffusion),也就是说像Stable Diffusion 这种专门用于图像生成任务扩散模型(Diffusion Model),中间就可以融入了 CLIP 或类似模型的文本嵌入,以实现 文本引导的图像生成。
论文:https://arxiv.org/abs/2103.00020
论文解读推荐:https://zhuanlan.zhihu.com/p/486857682
openclip-model-demo
为了进一步学习,我试图查询CLIP模型能否单独实现什么应用,进行模仿复现,但是大量检索结果表明,CLIP模型需要和其他算法配合使用,通过论文中的思想,我在笔记本上用pytorch简单训练了一个“MiniCLIP模型”,不过结果是发散的,没有足够的算力和技术支持很难进行训练复现。
因为openai本身没有开源CLIP的训练过程,我们可以学习OpenCLIP提供的代码(他们的代码相当精炼且优雅),我用他们训练出来的预训练模型实现了一个小demo,虽然就是运行模型没什么技术力,代码也比较零散,但是挺有意思(https://github.com/Krisnile/openclip-model-demo),如果有开发兴趣后期也可以做成一个比较大的图文检索系统或者信息聚合系统。
